This page showcases a list of projects developed by me and research that I’ve done over time. Order is random and does not depict popularity or timeline.
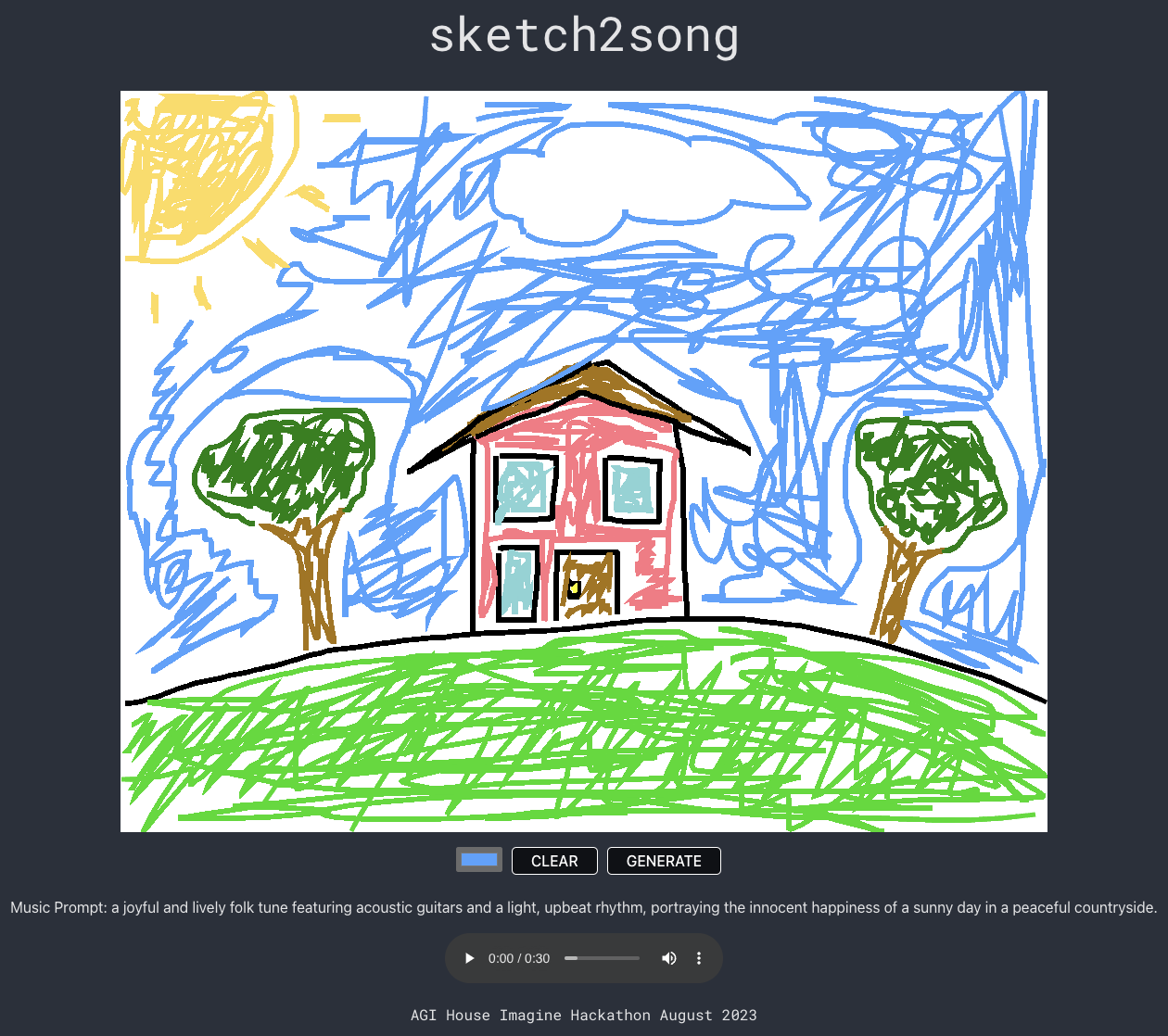
sketch2song 🏠 🤖 Third place at AGI House Imagine Hackathon 2023
We created a desktop web application on React and Flask that lets users draw a sketch on the canvas and automatically generate an acompanying song using the themes and emotions evoked from said sketch. We use InstructBLIP, ChatGPT, and MusicGen in our DL pipeline in order to generate the raw audio waveform. The sketch gets converted into an image, which is sent to InstructBLIP to extract a detailed caption describing the content of said image. After this, the caption is fed into a ChatGPT prompt designed to create a different prompt for MusicGen based on the image caption. Then, said MusicGen prompt is sent to MusicGen, and the resulting audio is finally sent back to the user. Feel free to check it out at sketch2song.com!
BEHAVIOR-1K ⭐ Nominated for best paper award at CoRL 2022
We introduce BEHAVIOR-1K, a comprehensive simulation benchmark for human-centered robotics, encompassing 1,000 everyday activities in diverse scenes with annotated objects. Its novel simulation environment, OmniGibson, supports realistic physics-based simulations, presenting challenges for state-of-the-art robot learning solutions. BEHAVIOR-1K’s human-grounded nature, diversity, and realism make it valuable for embodied AI and robot learning research. Read more about it here

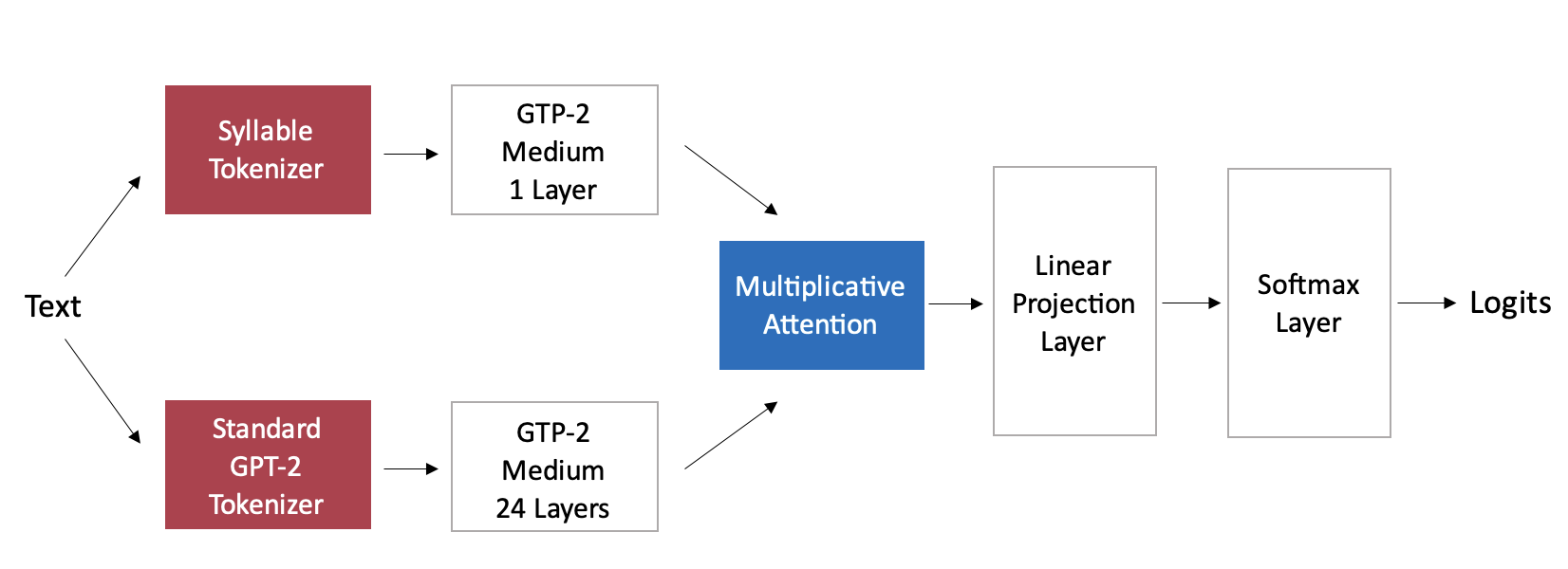
DeepRhymes
I worked on a controllable rap lyric generation system using GPT-2. The user supplies a set of words they wish to see in the resulting rap lyrics, and the model outputs rap lyrics incorporating those words. We fine-tuned a GPT-2 model on rap and poem verses and another modified GPT-2 model that contains a single layer which processes syllabic information. With a multiplicative attention layer, we combined the outputs of both the GPT-2 model and the syllabic module to generate the rap verses. We determined that fine-tuning on the last two layers of the original GTP-2 model and on all rap and poem verses resulted in the best performing model.
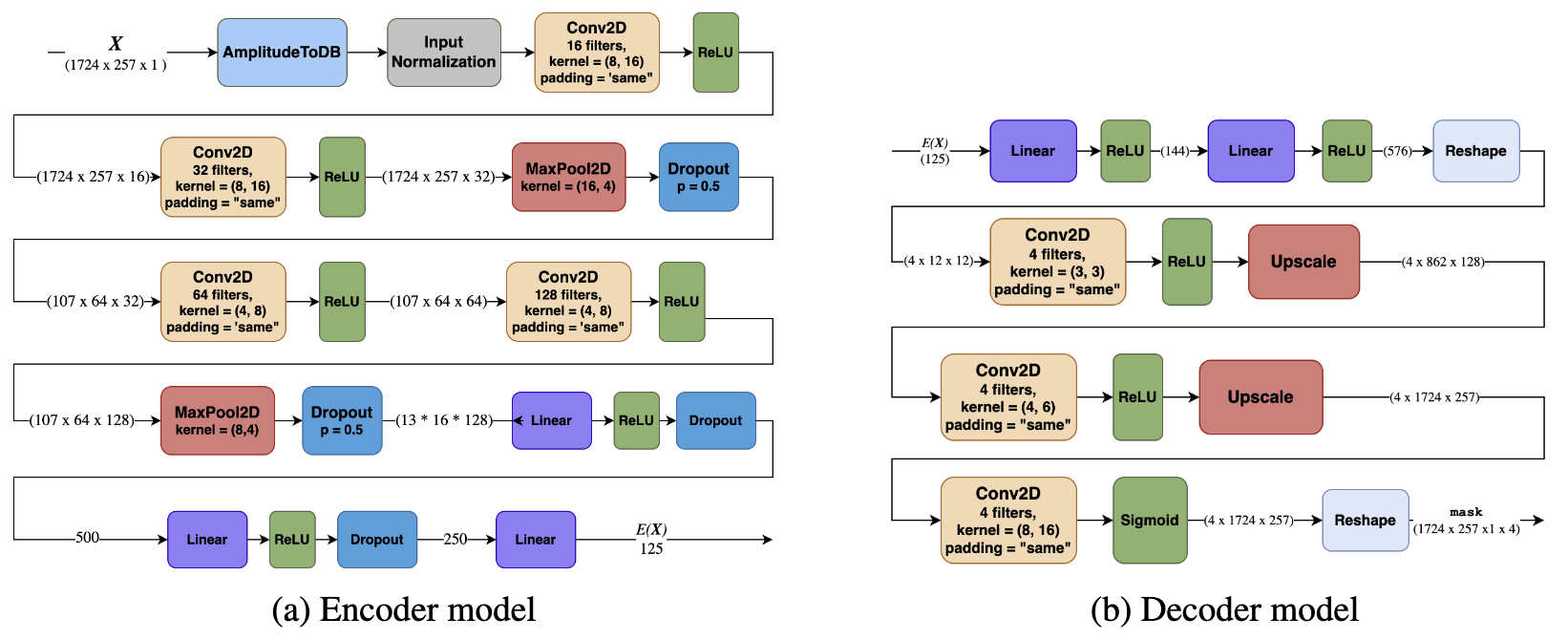
DeepDeMix
I worked on a music source separation system using deep learning! I propose the use of supervised contrastive pretraining for the task of music source separation. I hypothesized that the use of supervised contrastive learning, which is often used to learn useful representations for downstream tasks, can be applied to music source separation.
GuitarSynth
I created an ML system that takes as input a guitar and outputs a mosaic of sounds from a curated library of music! I can press on a pedal and record a guitar piece in order to hear back the fetched mosaic afterwards. I can press the pedal again to hear back the fetched mosaic simultaneously as I play guitar.
Accelerate
I created an interactive-fiction game using Twine! In 2073, the streets of San Francisco are rampant with crime, poverty, and political violence while a fraught political system run by AI tries to sustain it all. It centers around David Park-Garcia, former mercenary for one of the largest AGI corporations in the planet as he discovers the truth of this distopian world. Visit the website here to learn more!

Image Colorization with GANs and captioning
I worked on an image colorization system using GANs and captioning. We propose a method which combines both by using both image captioning and GANs to colorize grayscale images.

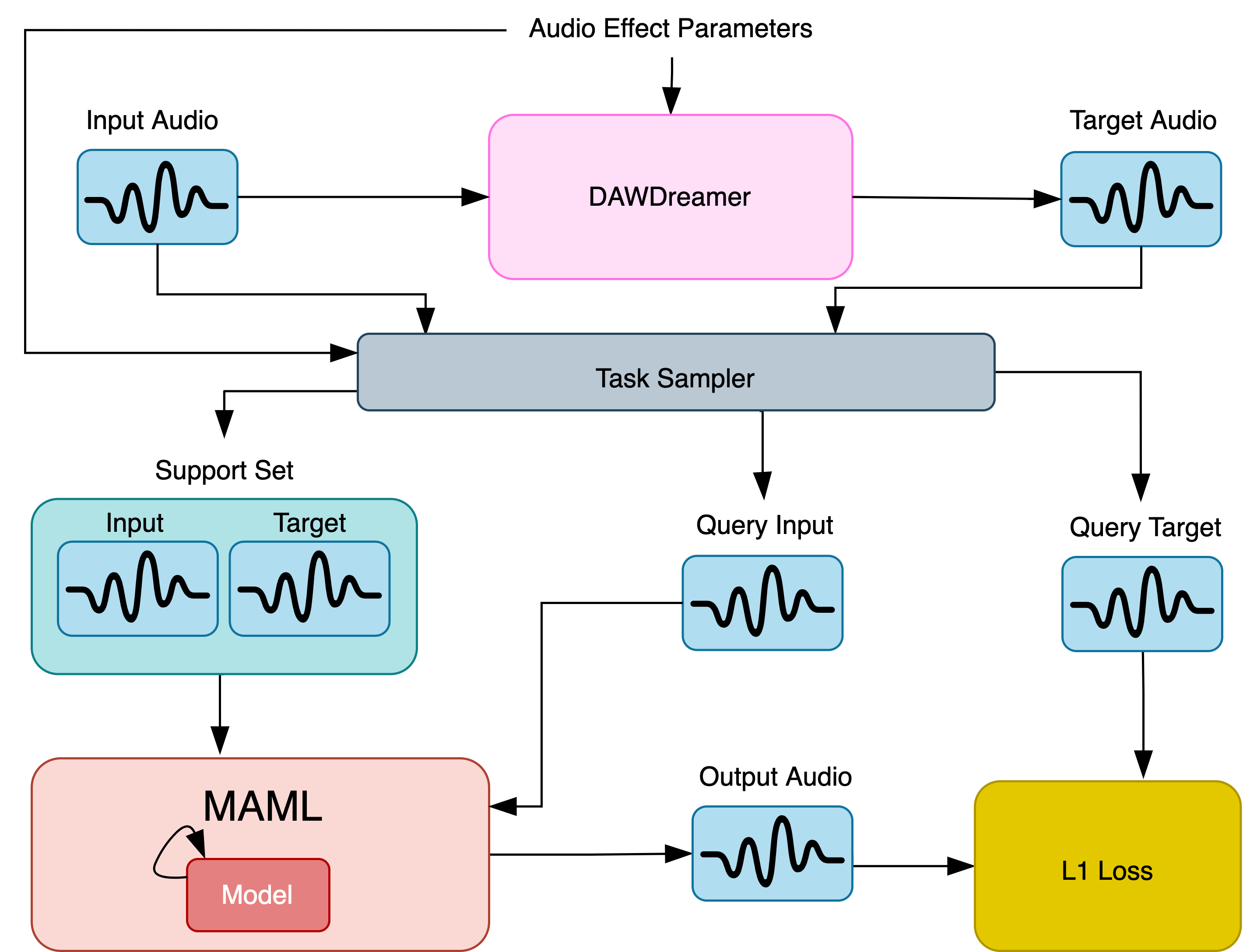
Meta-learning for digital audio effects
I worked on deep learning models that are able to meta-learn digital audio effects. We postulate that there exists a substantial amount of shared structure between different audio effects that can be exploited by meta-learning methods in order to learn multiple audio effects much more efficiently. This paper focuses on the implementation of MAML to exploit this shared structure and meta-learn these audio effects without access to the audio-effect parameters used to transform audio signals. We trained TCN, LSTM, and Transformer models using MAML on generated audio data in order to learn the audio effects applied.